
The promise of Industry 4.0 has many manufacturing leaders thinking big. They envision a future in which real-time access to data opens the door to unprecedented levels of operational flexibility, predictability, and business improvement. For many, early-stage wins often lead to larger projects that stall or fail to scale because their data infrastructure couldn’t support the increasing project complexity.
Enter Industrial DataOps.
DataOps (data operations) is the orchestration of people, processes, and technology to securely deliver trusted, ready-to-use data to all the systems and people who require it. The first known mention of the term “DataOps” came from technology consultant and InformationWeek contributing editor Lenny Liebmann in a 2014 blog post titled, “DataOps: Why Big Data Infrastructure Matters.”
According to Leibmann:
“You can’t simply throw data science over the wall and expect operations to deliver the performance you need in the production environment—any more than you can do the same with application code. That’s why DataOps—the discipline that ensures alignment between data science and infrastructure—is as important to Big Data success as DevOps is to application success.”
Enter Industrial DataOps.
DataOps (data operations) is the orchestration of people, processes, and technology to securely deliver trusted, ready-to-use data to all the systems and people who require it. The first known mention of the term “DataOps” came from technology consultant and InformationWeek contributing editor Lenny Liebmann in a 2014 blog post titled, “DataOps: Why Big Data Infrastructure Matters.”
According to Leibmann:
“You can’t simply throw data science over the wall and expect operations to deliver the performance you need in the production environment—any more than you can do the same with application code. That’s why DataOps—the discipline that ensures alignment between data science and infrastructure—is as important to Big Data success as DevOps is to application success.”
DataOps for Manufacturing
DataOps solutions are necessary in manufacturing environments where data must be aggregated from industrial automation assets and systems and then leveraged by business users throughout the company and its supply chain.
HighByte developed a DataOps solution specifically designed for the manufacturing industry called the Intelligence Hub. The platform allows manufacturers to create scalable models that standardize and contextualize industrial data. Over the years, we have worked with many manufacturers who are at varying stages of their DataOps implementation and have different goals.
That’s why we created this maturity model, to help readers like you understand where you are on your own journey—and where you need to go to achieve the results you expect. It’s a four-stage process that includes data access, data contextualization, site visibility, and enterprise visibility.
The successful attainment of each stage—and the benefits associated with them—is dependent on three parameters:
Let’s take a closer look at each stage and how the different parameters fit into the process. See Figure 1 below for an overview.
HighByte developed a DataOps solution specifically designed for the manufacturing industry called the Intelligence Hub. The platform allows manufacturers to create scalable models that standardize and contextualize industrial data. Over the years, we have worked with many manufacturers who are at varying stages of their DataOps implementation and have different goals.
That’s why we created this maturity model, to help readers like you understand where you are on your own journey—and where you need to go to achieve the results you expect. It’s a four-stage process that includes data access, data contextualization, site visibility, and enterprise visibility.
The successful attainment of each stage—and the benefits associated with them—is dependent on three parameters:
- Team
- Data handling
- Data structure
Let’s take a closer look at each stage and how the different parameters fit into the process. See Figure 1 below for an overview.
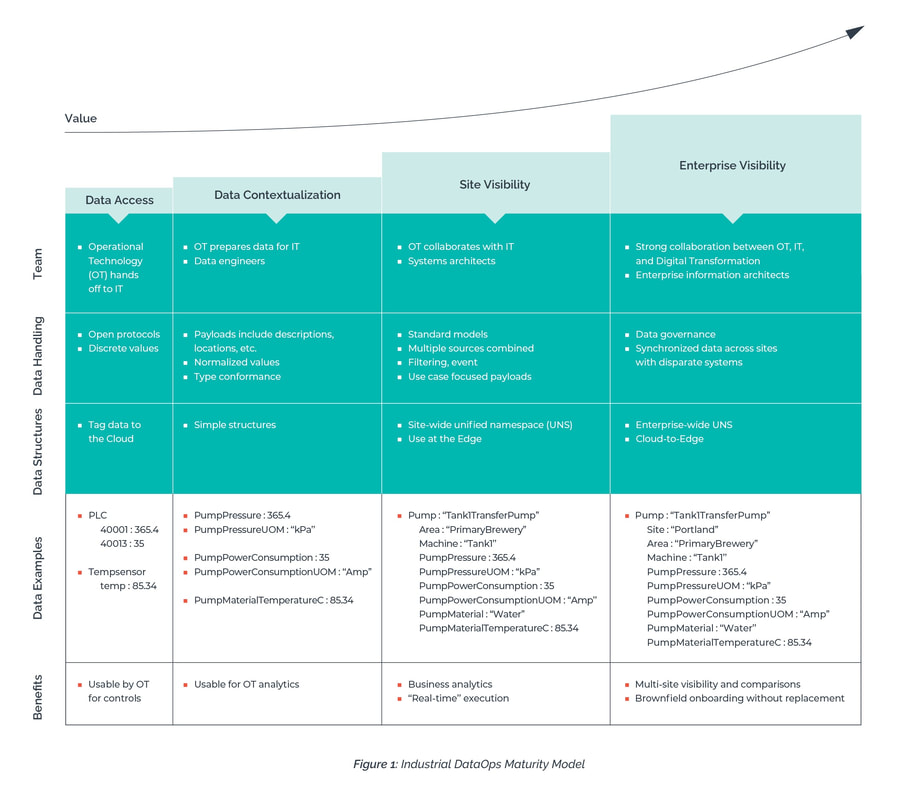
Stage One: Data Access
Data access requires the linking of APIs via open protocols to collect discrete values that might tell you about how various pieces of equipment are operating. An example may include power consumption, temperature, or pressure data points. At this stage, the data structure is tag data, and the data is typically being transported to the Cloud or a local database or data lake. Typically, the Operational Technology (OT) team will hand off the data to the IT team to store the data and there is not a strong collaboration to make the data more usable.
The data access stage is generally useful for optimizing controls and other key operational functions. However, many companies find the data is not suitable for higher-level business analytics or most use cases beyond process monitoring.
To determine whether you’re in the data access stage, ask yourself the following questions:
The data access stage is generally useful for optimizing controls and other key operational functions. However, many companies find the data is not suitable for higher-level business analytics or most use cases beyond process monitoring.
To determine whether you’re in the data access stage, ask yourself the following questions:
- Am I streaming PLC tag data or sensor-fed information directly to the Cloud?
- Is the OT team handing off the data to the IT team for unspecified usage?
- Am I primarily aiming to drive operational improvements?
Stage Two: Data Contextualization
Once you’ve collected and defined the data, you can begin creating models that include more descriptors, such as asset location and function. You begin to normalize values with common units of measure for a particular operation, such as pump flow. Type conformance is enforced to improve integration reliability. And the data structure at this stage is simple. The team—which now involves the OT team sending data to IT as well as data engineers—structures the information in a basic, more identifiable format.
The data contextualization stage provides contextualized and standardized data points to the operations team, enabling them to compare similar data points. The OT team benefits by having analytical information they can use to make more informed operating decisions.
To determine whether you’re in the data contextualization stage, ask yourself the following questions:
The data contextualization stage provides contextualized and standardized data points to the operations team, enabling them to compare similar data points. The OT team benefits by having analytical information they can use to make more informed operating decisions.
To determine whether you’re in the data contextualization stage, ask yourself the following questions:
- Are we creating simple structures to better define each data point for the data being sent to the Cloud?
- Am I now including descriptors with data delivery, such as location (including facility, line and/or work cell) or operational function?
- Do I have standard formats for presenting data from specific operations, including agreed-upon numerical values?
- Can the operations team derive strategic, analytical insights from the data?
Stage Three: Site Visibility
For sitewide visibility, you need standard logical models of information on work cells, assets, and lines. The enabling tool here is the unified namespace (UNS). A UNS is a consolidated, abstracted structure by which all business applications can consume real-time industrial data in a consistent manner. A UNS allows you to combine multiple values into a single, structured logical model that can be understood by business users and used sitewide, including at the Edge, to make real-time decisions.
The site visibility stage is focused on providing information payloads to business users outside of operations. This data is typically used to improve quality, research and development, asset maintenance, compliance, supply chain, and more.
To determine whether you’re in the site visibility stage, ask yourself the following questions:
The site visibility stage is focused on providing information payloads to business users outside of operations. This data is typically used to improve quality, research and development, asset maintenance, compliance, supply chain, and more.
To determine whether you’re in the site visibility stage, ask yourself the following questions:
- Am I combining data from multiple sources, such as MES data, with real-time sensor data?
- Can I filter event-based data rather than numeric descriptions?
- Can I use the data at the Edge?
- Are my systems architects, IT team, and OT team working collaboratively to contextualize data?
Stage Four: Enterprise Visibility
Enterprise-wide DataOps is similar to the site-specific stage in terms of data sophistication, but now you’re able to extend benefits across the entire business. In the enterprise visibility stage, you’re synchronizing data structures across multiple sites and disparate systems. You might have an enterprise-wide UNS and move data from the Cloud to the Edge. Meaning, you’re pushing analytics from the enterprise-level down to the factory floor. This is where end-to-end visibility becomes a reality. You can conduct site-to-site comparisons without having to rip-and-replace existing systems. This stage often requires much stronger collaboration among the OT, IT, and digital transformation teams. Enterprise information architects may also become involved in the data modeling process.
The enterprise visibility stage provides the broadest value to companies, allowing them to aggregate information across sites with common dashboards, metrics, and analytics. It also allows them to implement sophisticated data-driven decision making and Cloud-to-Edge automation.
To determine if you’ve achieved the enterprise visibility stage, ask yourself the following questions:
The enterprise visibility stage provides the broadest value to companies, allowing them to aggregate information across sites with common dashboards, metrics, and analytics. It also allows them to implement sophisticated data-driven decision making and Cloud-to-Edge automation.
To determine if you’ve achieved the enterprise visibility stage, ask yourself the following questions:
- Do I have multisite visibility and comparisons?
- Can I push data from the Cloud to the Edge?
- Can I achieve brownfield onboarding without replacement?
- Do I have strong collaboration among my OT, IT, and digital transformation teams?
Wrap Up
The key takeaway here is that you can’t achieve the benefits of enterprise visibility with the approach of data access.
Many companies have been sold the benefits of enterprise-wide data visibility and usage but do not recognize the data requirements to do so. Yes, we are in the age of APIs. However, when working with manufacturing data, it is not just about providing access to the data and letting the data scientists conjure business performance through artificial intelligence. Business users must work with the teams who support the factory, data must be curated, and solutions must be designed to be implemented at scale across the site and enterprise.
To learn more about how Industrial DataOps can help you achieve your digital transformation goals, download the white paper, “DataOps: The Missing Link in Your Industrial Data Architecture.” Or, if you’re ready to progress to the next stage, let's schedule a demo.
Many companies have been sold the benefits of enterprise-wide data visibility and usage but do not recognize the data requirements to do so. Yes, we are in the age of APIs. However, when working with manufacturing data, it is not just about providing access to the data and letting the data scientists conjure business performance through artificial intelligence. Business users must work with the teams who support the factory, data must be curated, and solutions must be designed to be implemented at scale across the site and enterprise.
To learn more about how Industrial DataOps can help you achieve your digital transformation goals, download the white paper, “DataOps: The Missing Link in Your Industrial Data Architecture.” Or, if you’re ready to progress to the next stage, let's schedule a demo.