Contextualized data is essential for Industry 4.0. Deploy HighByte Intelligence Hub at the Edge to access, model, transform, and prepare plant floor data for analysis in the Cloud.
HighByte Intelligence Hub was built for the unique qualities of industrial data. The software securely connects devices, files, databases, and systems via open standards and native connections. Use the interface to model streaming data in real time, normalize and standardize data points and data models inherent to diverse machinery, and add context to data payloads that otherwise lack descriptions. Tap into real-time and asset model data from a variety of edge data sources, including machine data, transactional data, and time series (historical) data.
HighByte Intelligence Hub was designed for scale. Simplify and accelerate the modeling of tens of thousands of datapoints from PLCs and machine controllers with re-usable models that transform raw data into comprehensive, useful information. Import and export template definitions to quickly replicate common datasets across assets. Efficiently deliver contextualized and correlated information to the applications that require it.
HighByte Intelligence Hub is an ideal solution for manufacturers and other industrial companies because the software was designed for Operational Technology (OT) teams. The platform-agnostic solution runs on-premises at the Edge, scales from embedded to server-grade computing platforms, and offers a code-free user interface. Administrators can configure a network of distributed hubs through a single management portal and deploy these hubs without downtime.


PRODUCT DEMO
This interactive product demo walks you through an overview of the Intelligence Hub. From Models to Pipelines and more, learn what makes the Intelligence Hub a powerful Industrial DataOps solution.
Reduce system integration time from months to hours
Improve data curation and preparation for AI and ML applications
Scale operations metrics and analytics across the enterprise
Reduce information wait time for business functions
Eliminate time spent troubleshooting broken integrations
Empower operators with insights from the Cloud
Improve system-wide security and data governance
Meet system integrity and regulatory traceability requirements
Reduce Cloud ingest, processing, storage costs, and complexity

Download the Solution Brief to learn more about critical features, measurable benefits, use cases, and technical specifications.
Collect and publish data over open standards and native connections—eliminating the need for custom-coded integrations. Easily configure and manage multiple connections and their respective inputs and outputs within the script-free interface. Collect data from SQL and REST source systems using dynamic requests leveraging inputs from other systems. Quickly integrate data from specialty systems and devices. Merge data from multiple systems into a complex modeled payload.
Collect and condition raw input data and then pass conditioned data to model instances or pipelines. Filter data through a deadband condition to reduce the jitter in a source sensor or measurement. Filter the data through an aggregate to buffer higher resolution data and provide statistical calculations using average, min, max, count, and delta at a slower rate to characterize the specified time period. Manipulate and transform raw input data into a usable format. Alarm on bad quality or stale data. Use the built-in transformation engine to standardize and normalize data for comparison and application mismatches. The transformation engine enables you to perform calculations, execute logic to define new “virtual property” values, and decompose complex strings at the Edge to improve data usability and reduce transmission volume. Define global JavaScript functions or load third-party JavaScript or Node packages, then use them in any expression within the Intelligence Hub.
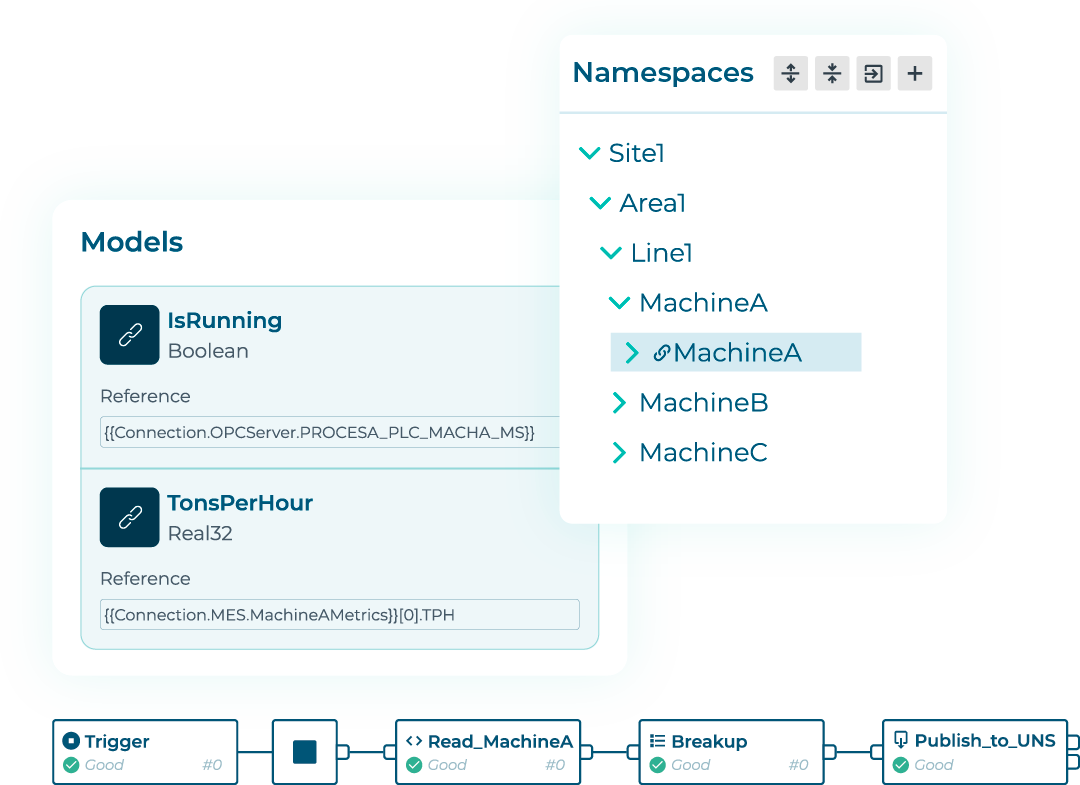
Represent machines, products, processes, and systems with intelligent data models suited to your needs. Contextualize thousands of industrial data points by merging them with information from other systems, adding meta data, standardizing data attribute names and lists, and normalizing units of measure. Model hundreds of common assets in minutes with templatized inputs and instances and manage models through an intuitive attribute tree that enables model nesting.
Use the graphical Pipelines builder to curate complex data payloads for everything from MQTT brokers to historians to data warehouses and track the transformation of data through the pipeline. Use stages to read, filter, buffer, transform, format, and compress payloads. Read within and across Namespace hierarchies using the Smart Query stage. Use the On Change stage to enable event-based delivery and report-by-exception of any data source. Use the Switch stage to introduce conditional logic to your pipeline and the Model Validation stage to assess incoming data payloads against a model definition. Iterate through data sets or paginate through APIs until specified conditions are met with the For Each and While stages. Reuse and share data processing routines using the Subpipeline stage.
Run HighByte Intelligence Hub on your choice of light-weight hardware platforms including single board computers, industrial switches, IoT gateways, and industrial data servers. Deploy as an individual software installation or Docker image to rapidly deploy and upgrade system software components.
Use DataOps for AI and AI for DataOps in HighByte Intelligence Hub. Build pipelines that can be exposed as custom MCP “tools” for agentic AI workflows. With the Industrial MCP Server, AI agents can access all connected industrial systems in the Intelligence Hub and make real-time or historical data requests on them. AI can also be used to scale Industrial DataOps. Use an LLM of your choice, such as Amazon Bedrock, Azure OpenAI, or Google Gemini, to map disparate data sources into data models and accelerate data contextualization. Conversationally build and debug pipelines with the in-app Pipeline AI Agent or through external agents via MCP configuration tools.
The REST Data Server acts as an API gateway for industrial data residing in OT systems, so any application or service with an HTTP client can securely request OT data in raw or modeled form directly from the Intelligence Hub—without requiring domain knowledge of the underlying systems. This API securely exposes the Intelligence Hub’s connections, models, instances, and pipelines as well as the underlying values. Use the REST Data Server with Callable Pipelines to gain an "Industrial Data API Builder" Connect to the REST Data Server to access the Intelligence Hub as a transactional, request-and-response interface and programmatically browse the full Industrial DataOps infrastructure.
Use the UNS client to visually discover and interrogate contents residing in any MQTT broker, negating the need for external testing clients. Simply select a connection and instantly visualize the namespace. The UNS Client can automatically detect and visualize message payloads including JSON, Sparkplug, text, and raw binary, and decode Protobuf to make payloads human readable for Sparkplug users. In addition to topic and message inspection, the UNS Client can also publish messages to topics.
